
在试管婴儿(IVF)的临床过程中,医生最纠结的时刻莫过于:面对培养皿里好几个看起来都不错的胚胎,到底该先移植哪一个?近年来,人工智能(AI)被寄予厚望,目前,主流的AI选胚胎模型通常被训练来预测单个胚胎活产的概率。在评估这些模型时,目前行业常见的评估指标是AUC(曲线下面积)。然而,本次介绍的论文指出:AUC衡量的是模型对大量胚胎样本的平均区分能力,但在真实临床中,医生面对的是同一患者的一组胚胎,需要从中选出最优的一个。因此,临床真正需要的也许不是单个胚胎的预测概率,而是AI在同一组胚胎中的排序能力。

研究创新
本文首先指出了当前胚胎评估AI研究中的一个重要问题:传统评价指标如AUC主要反映模型对单个胚胎结局的平均预测能力,但在真实临床情境中,医生需要在同一患者的一组胚胎中进行选择,因此单纯依赖AUC难以全面反映AI在胚胎挑选中的实际价值。在此基础上,研究提出从“排序能力”角度重新评估AI模型,并引入“严重失误率”这一指标,用于衡量模型是否会出现明显不合理的排序结果。同时,研究通过训练50个结构相同但随机初始化不同的模型,系统比较其排序结果,从而更接近真实临床决策场景,为评估AI在胚胎选择中的性能提供了新的视角。
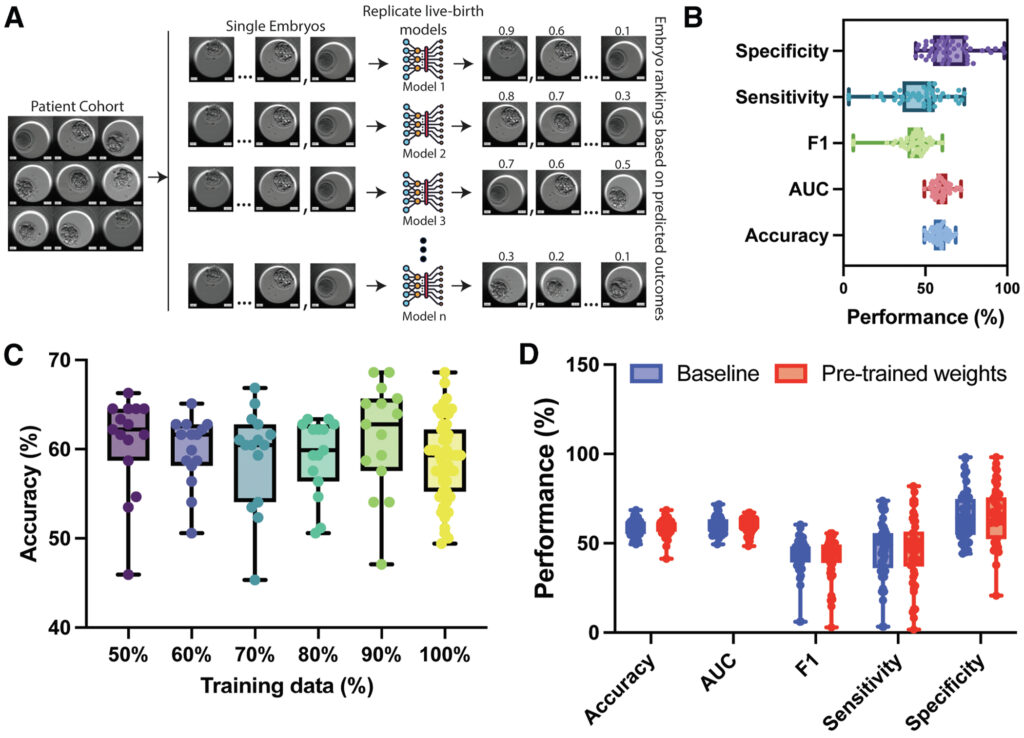
研究结果
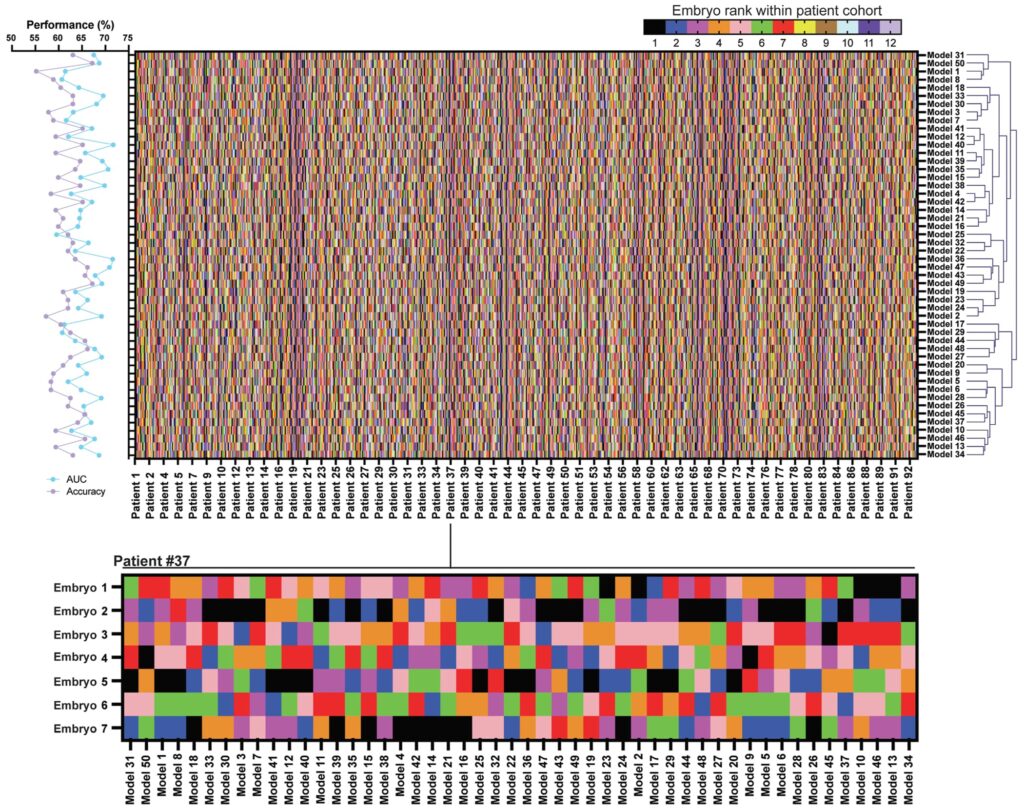
从传统指标来看,这些AI模型似乎表现尚可,平均预测性能约为0.60。但当研究者进一步比较不同模型给出的胚胎排序结果时,却发现一致性并不高。50个模型之间的排序协调系数仅约0.35,说明即使AUC几乎相同,不同模型在判断“哪一个胚胎最好”时仍可能给出不同答案。
研究还发现了一种更值得关注的情况。在约 15% 的病例中,一些模型会把明显发育潜力较低的胚胎排在第一位,而同一组中其实存在质量更好的囊胚。这类错误在整体统计指标中可能被平均掉,但在真实临床中却可能直接影响移植决策。研究者还通过可解释性分析发现,不同模型在图像中关注的胚胎结构区域也存在明显差异,这提示AI模型可能依赖不同的判断依据,从而做出完全不同的判断。
临床意义
这项研究带来的一个重要启示是:在IVF的人工智能评价体系中,排序能力远比单纯的预测能力重要。在IVF临床实践中,医生的任务通常不是判断某个胚胎“是否有潜力”,而是需要在同一患者的多个胚胎之间做出排序选择。即使AI的预测指标表现良好,也未必能够在多胚胎选择场景中提供稳定可靠的排序建议。
因此,未来在开发IVF人工智能模型时,可能需要进一步思考训练目标与临床任务之间的匹配问题。例如,在模型评估中引入更贴近临床决策的指标,如胚胎排序一致性、优先胚胎选择准确率等,而不仅仅依赖AUC等传统预测指标。只有当AI能够稳定地完成“胚胎排序”这一核心任务时,才更有可能真正成为临床决策的有效辅助工具。
研究局限
本研究的重点在于分析模型排序结果的一致性,而并未对不同模型结构或训练策略进行系统比较。因此,当前结果更多是在提示现有评估方式可能存在的局限,而不是对所有人工智能方法作出全面结论。另外,本研究训练的AI性能在行业内不算优秀,且没有评估那些已经在临床中使用的AI模型,不能代表目前IVF中AI的最佳表现。
结语
在人工智能快速进入医学领域的今天,高性能指标往往容易让人产生乐观预期。但这项研究提醒我们:统计学上的高分,并不一定完全对应临床决策的真实需求。在IVF治疗中,医生面对的并不是“某个胚胎是否有潜力”,而是需要在多个胚胎之间做出选择。因此,仅仅预测单个胚胎的结局概率,可能还不足以解决实际问题。未来IVF人工智能的发展,或许需要从单纯追求预测能力,逐渐转向更贴近临床决策的排序能力。只有当AI能够在同一组胚胎中给出合理且稳定的优先顺序时,它才更有可能真正成为临床医生可靠的辅助工具。